Post-Training Nemotron 3 on Lab

Post-Training Nemotron 3 on Lab
AI has moved from models to agents that go beyond solving individual problems and instead can execute on full broad scope projects through tool calls, sub-agent delegation, and iterations over long horizons.
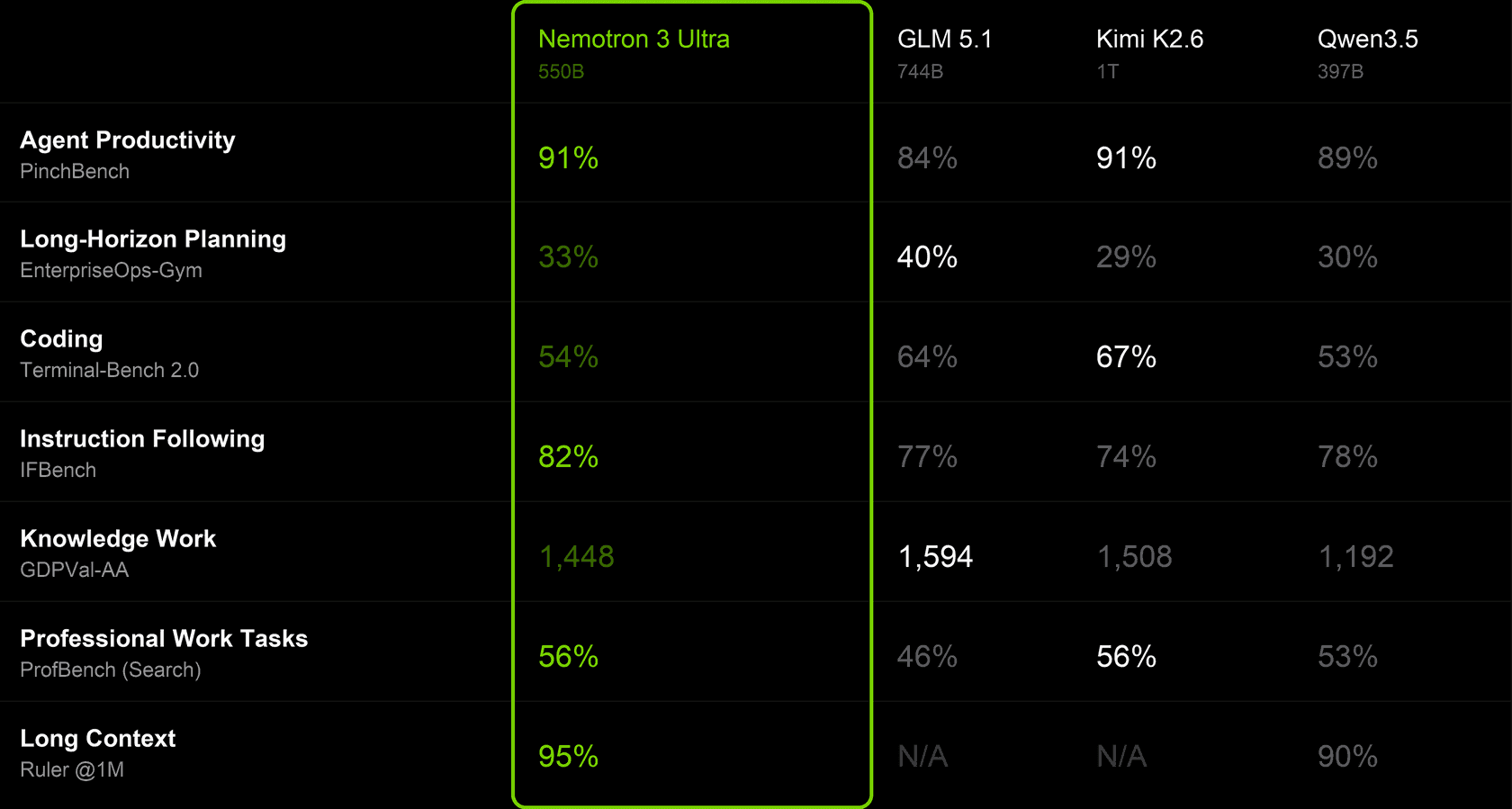
NVIDIA's Nemotron family is built for this paradigm. Nemotron 3 Ultra — a 550B-parameter Mixture-of-Experts model with 55B active parameters — is built for frontier reasoning and orchestration, with Nemotron 3.5 ASR for voice and Nemotron 3.5 Content Safety for guardrailing. Ultra sits at the open frontier out of the box: 95% on RULER@1M, 82% on IFBench, and 65–70.4% on SWE-bench Verified consistently across Pi, OpenHands, Hermes, OpenCode, and Mini SWE Agent.
A strong open model is the starting point of an agent. To specialize Nemotron 3 Ultra for your specific workflows and data, you need a repeatable post-training loop. Define the task, build the environment, run reinforcement learning (RL), evaluate, deploy, feed production traces back in, and repeat.
NVIDIA built Ultra with exactly this loop — it was post-trained using Multi-Teacher On-Policy Distillation in NVIDIA's open NeMo RL and Gym libraries. Lab enables you to do your own post-training — bring your workflow, your environment, your traces, and keep specializing Nemotron.
Teams are already using Prime Intellect Lab to post-train open models that outperform closed frontier systems on their own workflows, and the same hosted loop is now open for post-training Nemotron using Prime Intellect Hosted Training.
Day-0 Support for post-training Nemotron on Prime Intellect Lab
NVIDIA Nemotron 3 Ultra is fully supported on Prime Intellect Lab, our hosted post-training platform, with day-0 support for:
- Hosted RL training on Blackwell B200/B300 (and NVL72 where available), with native vLLM inference, NCCL weight broadcast, and the Prime-RL trainer.
- 2,500+ open RL environments in the Environments Hub, spanning SWE, agentic search, tool-use, math, science, cybersecurity, robotics sim, and more wrapped in our verifiers framework and runnable in Prime Sandbox.
- Hosted evaluations on the benchmarks Nemotron is targeting including SWE-bench Verified, BrowseComp, τ²-Bench Telecom, Terminal-Bench Hard, IFBench, AA-LCR, GPQA Diamond, RULER-1M. You can evaluate Nemotron and your training runs on dozens of relevant benchmarks.
- One-click inference with LoRA and full-weight adapters, served via NVIDIA Dynamo for efficient routing, autoscaling, and KV offloading.
- Continuous improvement loops using production traces flowing back into the next RL run, so your Nemotron-based agents can continuously improve with new data.
In the simplest case:
# Set up a Lab workspace with starter configs
prime lab setup
# Install an env from the Hub
prime env install primeintellect/opencode-swe
# Evaluate the new Nemotron Ultra on it
prime eval run opencode-swe -m nvidia/nemotron-3-ultra-550b-a55b --hosted
That's it. No cluster to stand up, no inference server to configure, no eval harness to plumb.
More documentation: https://docs.primeintellect.ai/hosted-training/getting-started
What RL on open envs does
We've been training and ablating open frontier models on our environment library for over a year. The numbers below are measured on INTELLECT-3.1 and similar open models on our stack
- SWE-bench Verified. Training on R2E-Gym-Subset-Validated (4.5k tasks) inside our minimalist bash + edit harness produces clean, monotonic gains for 30B-class MoE models.
- BrowseComp. Training INTELLECT-3.1 on the DeepDive environment lifted BrowseComp from 7.8% → 14.2% — one of the least-saturated benchmarks
- τ²-Bench Telecom. Our synthetic tau2-synth environment closely mirrors the real Telecom domain physics and reliably moves Telecom scores; the same factory generalizes to enterprise tool-calling.
- Reasoning RL stage. opencode-math, opencode-science, opencode-cp, and opencode-lean form the reasoning stage of every INTELLECT model and transfer cleanly to Nemotron-shape architectures.
A turnkey path for enterprises
The Nemotron family of open models is fast and built for agents. Enterprises should be able to ship an agent without having to create large internal RL infrastructure teams. That is exactly what Prime Intellect Lab is for.
With Lab, enterprises can:
- Start from Nemotron 3 Ultra out of the box (fully integrated on Prime Intellect Lab)
- Bring their own task (workflows, evals, mock or real data)
- Build or pick an environment — you can choose from 2,500+ open envs, or work with our applied research team to co-design a new one (in verifiers, runnable in Prime Sandbox)
- Run hosted RL — Lab handles trainer, inference, weight sync, checkpointing, and online evals on Blackwell
- Deploy with one click — we provide dedicated or serverless inference, native LoRA adapters, served via NVIDIA Dynamo
- Close the loop — log production traces to later feed back into the next training run for continual learning
The pattern is already in production:
- Ramp used Lab to post-train FastAsk, which is a 35B retrieval subagent (Qwen3.5-35B-A3B), on its own financial-spreadsheet workflow, reaching 66.25% exact-match accuracy versus Claude Opus 4.6's 61.88% (~4 points higher) at Haiku-class latency (~27% faster than Opus), and +10 points over its base model within hours of RL. The same hosted loop is what's now open for Nemotron.
- Zapier built AutomationBench on Lab and turned it from a static scorecard into a live RL training environment, catching reward hacking and fixing it in real time.
The same playbook now applies to Nemotron.
Why this matters for the open ecosystem
For the first time, the full post-training loop that closed labs run internally — environments, RL trainer, evals, inference, continuous learning — is openly available, on Blackwell, on a model family that already sits at the open frontier. That changes who can build agents that win:
- An AI-native startup can take Nemotron 3.5, post-train it on their own production traces, and create a frontier agentic model for their workflow.
- A large enterprise can keep all of it from model weights to training data to environment definitions inside their own sovereign deployment.
- An academic lab can run post-training experiments without breaking the bank
Every company is becoming an AI company, and the winners will own the loop: ship, learn, train, repeat. Nemotron gives the open ecosystem a frontier model built for agents. Prime Intellect gives every team the stack to make it theirs — on Blackwell, on open environments, in days
Get started
- Model card: NVIDIA Nemotron 3 Ultra 550B A55B BF16
- Environments Hub: Browse RL environments
- Docs: Read the docs
- Lab: Learn about Prime Intellect Lab
- Talk to us: Book a call · Start training