
Ramp used Prime Intellect Lab to train a retrieval subagent for Ramp Labs. The resulting FastAsk model outperformed Opus 4.6 while obtaining Haiku-level speeds at even lower costs.
At a Glance
- Trained Fast Ask, a specialist subagent for financial spreadsheet retrieval
- 27% faster and 4% more accurate than Claude Opus 4.6
- Haiku-class latency with 35B parameters
- 4x reward + 10% evaluation gain within hours of RL training
- Custom Ramp Sheets RL environment with 14 finance task types
- Model was given 3 tools and 15 turns to perform workbook navigation
- Shifted behavior from broad spreadsheet search to targeted, verifiable retrieval
Ramp Sheets FastAsk
Ramp Sheets is Ramp's AI spreadsheet editor for financial modeling and analysis. One of its core experiences is simple to describe and hard to build well: ask a question about a spreadsheet, get back an answer quickly, and trust that the answer was properly retrieved and computed from an agent navigating the workbook correctly and efficiently.
That is exactly what FastAsk is for.
FastAsk is a dedicated subagent for finding answers to questions like:
- Why did burn jump this month? Which vendors drove the spike?
- What is the outstanding balance for this customer?
- Which row has the invoice tied to this payment?
Frontier models can often answer these questions adequately, but they tend to be slow and cost-prohibitive for heavy usage. Ramp needed a model that was fast, lightweight, and specialized for a key workflow: efficiently navigate the spreadsheet, quickly find all the relevant information, do any necessary calculations, and answer precisely.
We worked with Ramp to train an agent exactly for this.
Training
With Prime Intellect Lab, Ramp turned their Ramp Sheets into a trainable RL environment. The FastAsk model learned to navigate workbooks, identify the relevant cells, and return precise answers to the main agent without forcing the primary model to spend its tokens on search.
Here is a representative task from the environment:
I am tightening our investor memo. What cumulative net recognized revenue did South land across 2025-03 to 2025-05, in USD cents?
Sheets: ['Orders', 'OrderLines', 'Shipments', 'Returns', 'OrderMonthNet', 'FxExposure', 'Contracts', 'FXRates', 'Targets', 'HiringPlan', 'CapTable']
In one successful rollout, the model handled this cleanly.
- It called workbook metadata first.
- It noticed there was a helper summary sheet called
OrderMonthNet. - It read a small slice of that sheet to understand the columns.
- It read a narrow region/month slice to find the relevant South rows.
- It pulled one more targeted slice around those rows.
- Then it used Python once to do the final aggregation.
That entire trajectory took just five tool calls: one metadata call, three reads, and one Python call. It read 513 cells total, and the final answer was:
ANSWER: 44164450
The model does not dump the whole workbook or wander through every tab. It notices the useful summary sheet, zooms in, computes, and finishes. That is the Fast Ask behavior we were trying to train.
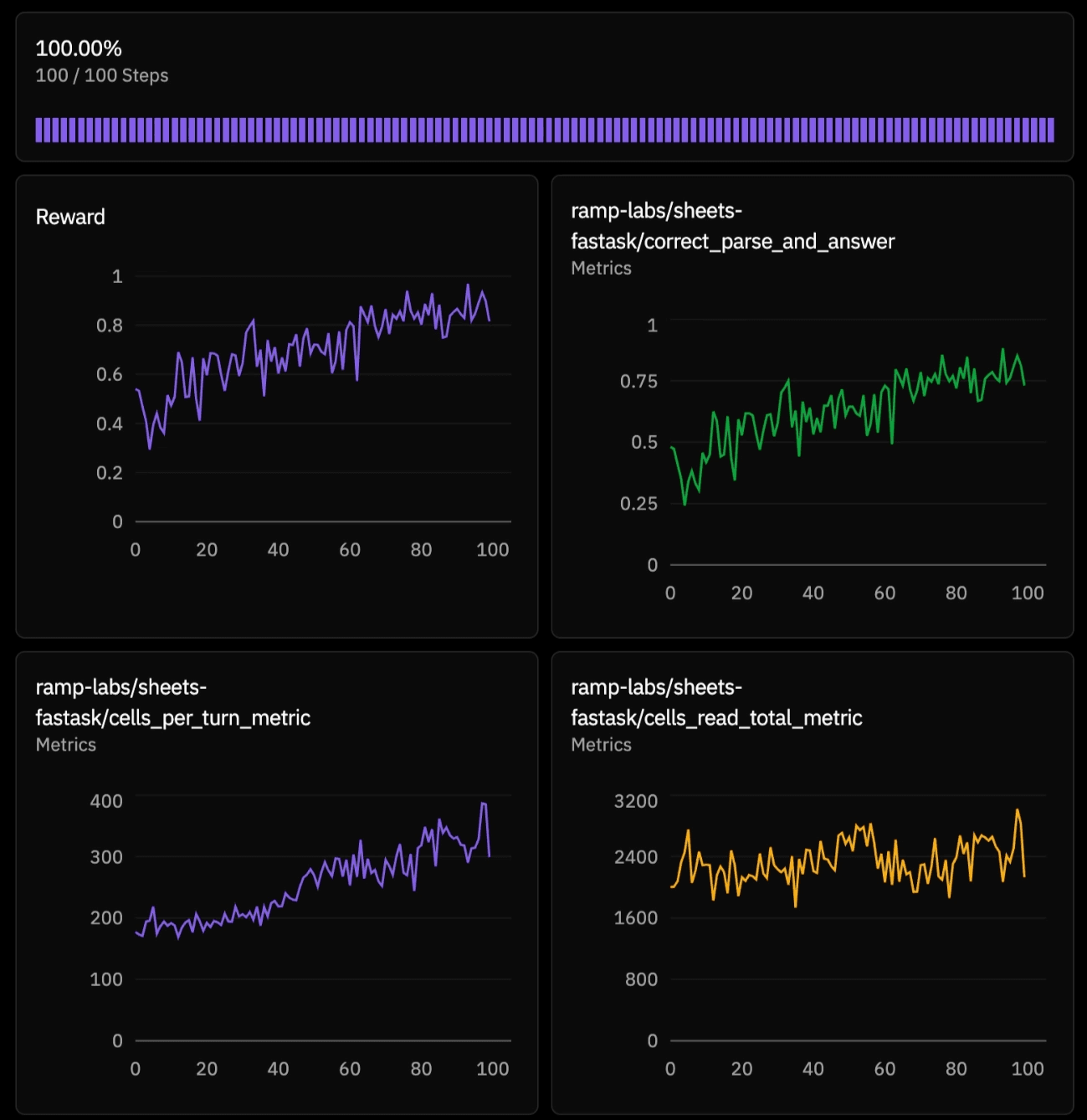
Results
Ramp selected Qwen3.5-35B-A3B as a base model, as it offered a Haiku-class latency profile, yet still struggled on hard retrieval tasks. Within hours of reinforcement learning, FastAsk beat Claude Opus 4.6 by 4+ points on exact-match accuracy and improved 10 points over its base model on a held-out evaluation set, all while preserving latency and cost-effectiveness.
We evaluated both the initial and trained model against the current Claude family of models on a hold-out set, measuring both wall-clock time and accuracy:
| Model | Accuracy | Time vs Haiku 4.5 |
|---|---|---|
| Qwen3.5-35B-A3B (FastAsk) | 66.25% | 1.05x |
| Claude Opus 4.6 | 61.88% | 1.44x |
| Claude Sonnet 4.6 | 59.38% | 1.60x |
| Qwen3.5-35B-A3B | 56.25% | 1.34x |
| Claude Haiku 4.5 | 51.88% | 1.00x |
Accuracy here is exact task completion. Time is mean per-rollout elapsed time, normalized to Haiku 4.5, so lower is better. All models are evaluated in "non-thinking" mode.
The bigger shift is that Ramp did not need to wait for a better frontier model. They took a narrow, high value product bottleneck, built an environment around it, and trained a smaller model to get better at the exact workflow that mattered. That is the real business impact that showed faster spreadsheet automation, higher task accuracy, and a path to AI systems that improve directly from the workflows they are used for.
Read the research blog from Ramp Labs here.