renderers: Token-Level Templating for Agentic RL

renderers: Token-Level Templating for Agentic RL
Today we're open-sourcing renderers, a standalone Python library that gives developers full control over conversation formatting for RL and multi-turn inference. The renderer abstraction, introduced by OpenAI's Harmony template for gpt-oss and popularized by Thinking Machines' Tinker cookbook, turns model chat templates into programmable Python objects. Instead of treating a chat template as a black-box Jinja string that formats messages, renderers exposes the operations RL systems actually need: rendering messages to token ids, parsing completions back into structured assistant messages, attributing tokens to source messages for loss masking, and extending multi-turn rollouts without re-rendering model-sampled history.
At Prime Intellect, we use renderers across our Lab product, as well as in verifiers and prime-rl. It has helped us reduce redundant tokenization, avoid chat-template breaks that previously created redundant training tokens, and make Token-In, Token-Out the default primitive for stable multi-turn RL.
This post dives into the many complex templating challenges that emerge in agentic RL, and how renderers allows us to solve them, including:
- re-tokenization drift from greedily sampled model completions
- lossy many-to-one tool parsing from "gold standard" templates
- subtle inconsistencies in whitespace padding
- 3x redundancy savings for packed training sequences
The design of renderers is grounded in multiple conclusions from our explorations:
- For RL, the inference server should be a simple token-only endpoint.
- Environments should be oblivious to tokenizers, and usable as evals for arbitrary model APIs.
- Every assumption one could make about a chat template will be violated eventually.
- Official chat templates are often "wrong" and require explicit opt-in repair.
The renderers library is standalone, ships with support for most popular open-weights models today, and is designed for drop-in portability across inference engines. We are collaborating with leading open-source partners, including NVIDIA, vLLM, and SGLang, to ensure renderers can become a useful reference standard across inference and RL infrastructure for the broader ecosystem.
How renderers works
A renderer is a structured translation layer between human-facing conversation objects and the token sequences a model actually consumes and produces. It defines the text↔token boundary intentionally: how messages become model-ready token ids, how sampled token ids become structured assistant messages again, and which parts of the resulting sequence should be trained on.
from transformers import AutoTokenizer
from renderers import create_renderer
tok = AutoTokenizer.from_pretrained("Qwen/Qwen3-8B")
rdr = create_renderer(tok, renderer="auto")
messages = [{"role": "user", "content": "hi"}]
prompt_ids = rdr.render_ids(messages, add_generation_prompt=True)
# Feed prompt_ids to a Token-In, Token-Out generation endpoint.
# The endpoint returns completion_ids sampled by the model.
parsed = rdr.parse_response(completion_ids)
# ParsedResponse(content=..., reasoning_content=..., tool_calls=...)
The important part is that the renderer works at the token boundary, not only the string boundary. It can parse special-token-delimited tool calls by id, preserve sampled completions exactly across turns, and attach a message_indices array to rendered tokens so the trainer can derive a loss mask without repeatedly diffing prompts.
For multi-turn rollouts, the key operation is bridge_to_next_turn:
next_prompt_ids = rdr.bridge_to_next_turn(
previous_prompt_ids=prompt_ids,
previous_completion_ids=completion_ids,
new_messages=[{"role": "tool", "content": "..."}],
)
The bridge returns the next turn's prompt ids by preserving the previous sampled stream verbatim and appending only the new environment messages plus the next assistant opener. If the previous turn was truncated, the renderer can synthesize the model's canonical turn-close token as non-loss prompt context. If the extension is not provably safe, it returns None and the caller can fall back to a full render — still using raw decoded bytes from prior sampled ids rather than a parsed dict.
renderers currently includes hand-coded renderers for Qwen3, Qwen3.5, GLM-4.5, GLM-5, MiniMax-M2, DeepSeek-V3, Kimi K2 / K2.5, Nemotron-3, and GPT-OSS, plus a DefaultRenderer fallback. It is available on PyPI:
uv add renderers
Why renderers
One way to think about renderers is as chat templates made programmable: easier to read, test, and reason about in Python than in Jinja. There is truth to that, and it clarifies an important boundary. A Jinja chat template can describe how structured messages become text, but it does not by itself define the inverse and adjacent operations RL systems need: parsing sampled tokens back into structure, attributing tokens for loss masking, or safely extending a prior token stream without re-rendering sampled history.
Renderers make those capabilities explicit — and just as importantly, they make the limits explicit. Their job is to preserve prefix continuity by default: a next-turn prompt should extend the prior sampled token stream exactly, unless the system intentionally changes that stream, for example through compaction.
That invariant is easy to state and surprisingly easy to break. The hard part is not rendering the first prompt. It is preserving token identity across the full round trip: sampled tokens become text, text becomes parsed structure, parsed structure becomes history, history becomes a new prompt, and that prompt becomes tokens again.
The rest of this section is the story of moving the source of truth closer to the model: first from messages, then to sampled token ids, and finally to renderers as the layer that controls the translation between them.
Stage 1 — Message-In, Token-Out
The natural starting point is Message-In, Token-Out: represent each conversation as a list of message dicts and send those messages to the inference server on every turn. The server applies its own chat template, tokenizes the rendered prompt, samples a completion, parses tool calls and reasoning out of that completion, and returns a structured assistant message. The client appends that assistant message to history and sends the updated history on the next turn. Later, the trainer reconstructs the rollout by running its own apply_chat_template over the recorded message list.
This is the API most inference servers make easy. It is also the wrong abstraction for RL.
The visible failure is parser round-tripping. Suppose the model emits the literal bytes for a boolean parameter:
prev stream: '<parameter=dry_run>\nfalse\n</parameter>'
re-rendered: '<parameter=dry_run>\nFalse\n</parameter>'
The server's tool-call parser turned false into a Python boolean. On the next render, Python stringification turns it into False. The semantic value is the same; the bytes are not. The next prompt no longer extends the previous sampled stream.
Boolean stringification is only the easy-to-see version. The same shape appears whenever the sampled stream is turned into a higher-level representation and later reconstructed: whitespace canonicalized by json.dumps, reordered fields, empty parameter blocks dropped because the dict has no field for them, special-token handling changed between components, or a tokenizer choosing a different BPE segmentation after detokenization and retokenization.
The details differ, but the failure is the same: the rollout still looks like the same conversation, yet turn N+1 no longer extends the exact token stream sampled through turn N. Message-In, Token-Out cannot guarantee that invariant because its source of truth is the message story, and messages are not tokens. Once the model's sampled bytes have been parsed, normalized, detokenized, and re-rendered, token identity has already been put at risk.
The fix is to stop reconstructing history from parsed messages and stop retokenizing model-sampled text. That leads to Token-In, Token-Out.
Stage 2 — Generic Token-In, Token-Out
Our first move was to make the inference endpoint accept prompt token ids directly. In our stack, that was a custom chat-completions route, /v1/chat/completions/tokens, implemented as a vLLM extension. The route accepts both messages= and tokens=. When tokens= is supplied, vLLM uses those token ids directly as the prompt.
The rollout loop records the server's emitted token ids on every turn and reuses them as the prefix for the next turn:
prev_turn_ids = step["tokens"]["prompt_ids"] + step["tokens"]["completion_ids"]
prompt_ids_next = prev_turn_ids + bridge_ids
prev_turn_ids comes from the server and preserves the sampled stream. Only bridge_ids is new: the tokens for incoming environment messages plus the generation prompt for the next assistant turn.
The generic bridge computed those ids by rendering a dummy assistant turn together with the new environment messages, then subtracting the render of the dummy assistant alone:
bridge_full = tokenize([dummy_assistant] + env_messages, ...)
bridge_base = tokenize([dummy_assistant], ...)
bridge_ids = bridge_full[len(bridge_base) - gap:]
The dummy gave the chat template something to attach the inter-turn separator to, without re-rendering the actual model output. Per-model work stayed on vLLM's side through /tokenize, so the client did not need hand-coded model logic.
This solved the biggest Message-In, Token-Out problem: the previous assistant turn stayed token-native. The actual sampled completion was not parsed into a dict and rendered again, so boolean normalization, whitespace changes, BPE retokenization drift, and template editing of prior assistant content mostly disappeared.
But the bridge was still a trick. It assumed that "render a dummy assistant plus new environment messages, subtract the dummy render, and keep the suffix" was equivalent to the true next-turn render. Sometimes that assumption held. Sometimes it did not. Chat templates are allowed to depend on global conversation shape, role order, tool state, generation-prompt flags, or special cases around the last assistant turn. The dummy changes that context. When it does, the suffix we extract can be a plausible bridge without being the correct bridge.
Some failures were loud: Qwen3.5-style templates can raise errors such as No user query found in messages. when the synthetic conversation shape violates template assumptions. Others were silent: the bridge looked reasonable as text but did not extend the prefix correctly at the token level.
Generic Token-In, Token-Out also had a truncation problem. The bridge implicitly assumed the previous completion ended with the model's canonical turn-close token. On a clean stop, that token was already emitted. On truncation, for example when max_tokens was hit, it was missing. A generic bridge could not know, for every model family, which close token to synthesize, where it belonged, or whether adding it was safe. The implementation handled this by giving up:
if is_truncated:
self.logger.debug("TITO: truncated completion, falling back to MITO")
return None
Returning None meant falling back to plain messages-only chat completions. In other words, the exact path we built Token-In, Token-Out to avoid.
Truncation was not the only escape hatch. Bridge tokenization could fail. Environment responses could have shapes the generic validator did not expect. Message-list prefix matching across stored trajectory steps could miss. Each case returned to Message-In, Token-Out, bringing back parser drift, BPE drift, and template editing.
The lesson was that Token-In, Token-Out was the right primitive, but the bridge could not remain generic. The client needed model-family knowledge: how to synthesize canonical turn closes, where role markers go, which tokens delimit tools and reasoning, when a template's dummy render is invalid, and how to extend by ids rather than by message-list prefix matching.
That became renderers.
Stage 3 — renderers
renderers closes the escape hatches by making the model-specific bridge explicit.
Each renderer implements bridge_to_next_turn in plain Python, matching the relevant model family's chat framing byte-for-byte where parity matters. The renderer knows what to emit when the previous turn was truncated, where role markers belong, how tool and reasoning sections are delimited, and when an extension is unsafe.
When the bridge cannot be applied safely, it returns None. The caller can then fall back to a full render(), but that fallback operates on raw decoded bytes preserved from the previous completion_ids, not on a parsed dict that may have canonicalized the model's output.
What a stable prefix buys us
The previous sections focused on why prefix breaks happen. The practical reason we care so much is that prefix continuity is what lets a multi-turn rollout become one efficient training sample.
When the invariant holds, the rollout is one contiguous token stream. It starts with the initial prompt, then alternates between model completions and the new prompt tokens introduced before the next turn: tool results, user follow-ups, role markers, and the next assistant opener.
prompt_ids_1
+ completion_ids_1
+ continuation_ids_2 + completion_ids_2
+ ...
+ continuation_ids_N + completion_ids_N
A loss mask marks assistant tokens as trainable and everything else as context. The trainer can run one forward/backward pass over the sequence; earlier turns are encoded once, while gradients still flow through every assistant turn.
That packing is only valid because each next prompt extends the previous sampled stream. Formally, for each turn:
prompt_ids_{t+1} = prompt_ids_t + completion_ids_t + continuation_ids_{t+1}
If turn t+1 does not extend turn t byte-for-byte, there is no single contiguous sequence whose prefix relation matches the prompts actually used during the rollout.
To train the later completions with their exact prefixes, the trainer has to start a new sample at the break. Everything before the broken boundary becomes prompt context, and training continues only on the completion tokens after that point. If another boundary breaks later, the same thing happens again.
That keeps the token prefixes correct, but it turns one rollout into multiple training samples. Every downstream sample pays again to encode the prefix. A five-turn rollout where every boundary fails to merge can become five samples carrying prefixes of length 1, 2, 3, 4, 5 turns. That is roughly 15 turn-lengths of forward-pass work instead of 5, or about 3x the clean compute.
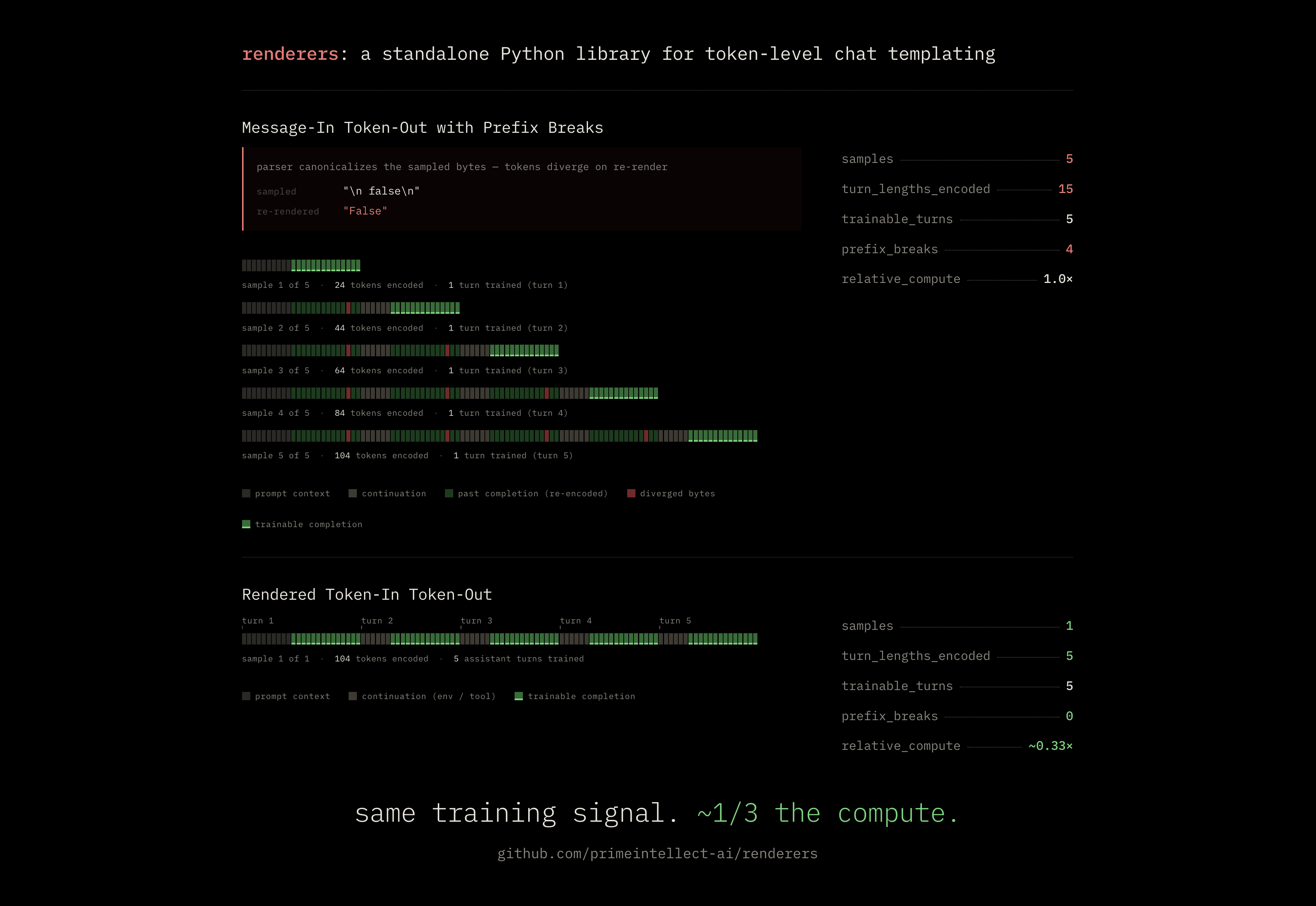
The extension property is what makes the efficient packed sample valid.
Design: the renderer protocol and the bridge
The previous sections describe the invariant: preserve the sampled token prefix unless the system intentionally rewrites it. The renderer protocol is the interface we use to enforce that invariant. Each method corresponds to one translation that used to be implicit, duplicated, or hidden inside a chat template.
The most important shift is the bridge. Generic TITO tried to infer the bridge by rendering a dummy assistant turn and taking a suffix. A renderer does not infer it. If we know the chat template, we can implement the bridge directly and make it exact for that model family.
Every renderer implements a small protocol:
class Renderer(Protocol):
def render(messages, *, tools=None, add_generation_prompt=False) -> RenderedTokens: ...
def render_ids(messages, *, tools=None, add_generation_prompt=False) -> list[int]: ...
def parse_response(token_ids) -> ParsedResponse: ...
def get_stop_token_ids() -> list[int]: ...
def bridge_to_next_turn(
previous_prompt_ids,
previous_completion_ids,
new_messages,
*,
tools=None,
) -> list[int] | None: ...
render returns a RenderedTokens object carrying both token_ids and message_indices. message_indices has one entry per token and attributes each token to its source message, or to -1 for structural scaffolding such as role wrappers and generation prompts.
That makes loss-mask construction a one-pass operation:
loss_mask = [
role_to_mask(messages[idx]) if idx >= 0 else False
for idx in rendered.message_indices
]
This is what lets build_training_sample assemble a training sample with one render call, instead of rendering once per turn and diffing prefixes to recover boundaries.
parse_response also works on token ids. It scans for special-token ids, such as the id for <tool_call> on Qwen3, and only decodes text segments between them. A literal string like "<tool_call>" inside user content tokenizes to ordinary text ids, not to the model's special-token id, so id-level parsing avoids false positives that decoded-text regexes can introduce.
The property test that ties the protocol together is the round trip: render a conversation containing an assistant message with content, reasoning, and tool calls; slice out the assistant completion; parse it; and assert that the parsed message is equivalent to the original structured assistant message.
The bridge
bridge_to_next_turn is where generic TITO becomes a renderer. It makes the extension property a first-class API.
Its contract is:
Given a previous turn's
(prompt_ids, completion_ids)and a list of new environment messages — tool results, user follow-ups, never assistant messages — return the ids for the next turn's prompt such that the result starts withprevious_prompt_ids + previous_completion_idsbyte-for-byte and continues with the new messages plus the next assistant opener. If that cannot be proven safe, returnNone.
Because the renderer knows the model family's chat template, the bridge no longer has to guess at a suffix. It can produce exactly the tokens the template would have produced for the new turn, while preserving the sampled prefix verbatim.
Every bridge does three things.
First, it anchors at the previous turn close. It walks backward through previous_completion_ids to find the model's canonical close token. On clean stops, the sampled completion already includes it. On truncated stops, the renderer synthesizes the canonical close as prompt context, with loss_mask=False, so the trainer does not compute loss on a token the model never produced.
Second, it refuses assistant content in the extension. New messages may include tool outputs or user follow-ups, but not assistant turns. Re-rendering assistant content would replace sampled bytes with canonical template bytes, which is exactly what the bridge exists to avoid.
Third, it renders only the new messages in the exact framing that model family expects. Qwen-style renderers know <|im_start|>role\n...<|im_end|>\n framing. GLM-style renderers know their own role-marker and turn-ending conventions. The point is not to invent a universal abstraction; the point is to encode the small amount of model-specific knowledge that makes the token stream correct.
Where the renderer boundary ends
Renderers make the message/text/token boundary explicit, but they do not make the rest of the stack information-preserving by default. They can preserve prefix continuity only if the sampled token stream remains the source of truth. Two adjacent layers matter here: chat templates and harnesses.
The first boundary is the chat template itself. Some templates intentionally rewrite history, for example by stripping old <think>...</think> blocks from prior assistant turns. This used to be a sensible default for avoiding context-window overflows. For RL, those savings come at the wrong layer: the stripped tokens were part of the sampled trajectory, and removing them changes the history the trainer is trying to reproduce.
A renderer that claims strict parity with that template would reproduce the stripping. Preserving the RL trajectory requires an intentional divergence: the renderer keeps the sampled bytes and marks that divergence in parity tests. That is a controlled disagreement, not something the renderer can derive automatically. When designing chat templates, it is worth making these policy choices explicit, and ideally exposing information-preserving variants for systems that need them.
The second boundary is the harness. Harnesses can break prefix continuity in many ways: repairing tool calls, reordering tool definitions, normalizing arguments, pruning or compacting old tool results, replacing multimodal blocks with summaries, or otherwise rewriting earlier history before the next model call. Each change may be useful for execution or context management, but if it silently mutates sampled history, the next prompt contains bytes the model never emitted.
We hit this with opencode's AI-SDK experimental_repairToolCall hook, which can rewrite Bash to bash or synthesize an invalid tool call. A renderer cannot fix that after the fact, because the drift happened before rendering. For optimal RL-ability, sampled history should remain immutable unless the system is intentionally rewriting it, as in compaction. Execution repair should not silently become history mutation; if a rewrite happens, it should be recorded as an explicit event that the trainer can model.
Closing
For agentic RL, the inference server should be a simple Token-In, Token-Out endpoint.
Every other operation — chat template application, parsing, reasoning extraction, tool-call handling, multi-turn stitching, and loss-mask construction — should happen in client code you control and can unit-test.
This is not simply design-pattern purism. In multi-turn RL, token identity determines whether a rollout can be reproduced, packed, and trained on efficiently.
renderers is the layer that makes this invariant explicit and testable in the Prime stack. We already use it in verifiers and prime-rl, and today we are open-sourcing it as a standalone package:
pip install renderers
Source code is available at github.com/PrimeIntellect-ai/renderers.
Start training your own models today with Prime Intellect Lab.